얼마전에 gcc와 clang이 정렬되지 않은 구조체(예를 들어 구조체의 크기가 7바이트) 를 어떤식으로 메모리에 배치하는지 테스트하다가 재밌는 현상을 발견해서 간단하게 정리했다.
스택에 지역변수가 어떤 순서로 쌓일까?
C/C++의 경우 지역변수는 스택에 배치된다. 함수에서 두개의 지역변수를 만들자. (각각의 지역변수를 x, y라고 부르자) 두개의 지역변수는 메모리의 어떤 주소에 배치될 것이다. 이때 x, y 중에서 어떤 변수의 메모리 주소값이 높을까? 이를 확인해보려고 아래의 코드를 작성해서 실행해보았다.
#include <stdio.h>
int main()
{
int x;
int y;
int diff = (unsigned long)&x - (unsigned long)&y;
printf("addr x : %lx\n", (unsigned long)&x);
printf("addr y : %lx\n", (unsigned long)&y);
printf("addr diff: %d\n", diff);
return 0;
}gcc simple.c -W -Wall
./a.out
addr x : 7fffcb2d08a4
addr y : 7fffcb2d08a8
addr diff: -4gcc의 경우는 y의 주소값이 더 높다.
clang simple.c -W -Wall
./a.out
addr x : 7fff5918a928
addr y : 7fff5918a924
addr diff: 4clang의 경우는 x의 주소값이 더 높다.
테스트해보니까 어떤 컴파일러로 컴파일해서 실행하느냐에 따라서 지역변수 x, y가 배치되는 순서가 다르더라. 컴파일러마다 행동이 다른걸 보니 정의되지 않은 행동(Undefined behavior)로 보인다. blog-undefined-behavior
처음에는 이상하다고 생각했지만 최적화할 수 있는 가능성을 열어둔다는 측면에서 지역변수의 순서를 스펙으로 강요하지 않은게 이해되더라. 게다가 일반적인 코드에서는 지역변수의 메모리 주소를 직접 확인할 일이 없으니까 별 문제도 없을테고.
하지만 이것을 이용하면 재밌는 흑마법을 쓸 수 있겠다는 생각이 들었다. 지역변수가 스택에 어떻게 배치되는지와 인덱스를 벗어난 배열 조회를 합치면 재밌는걸 할 수 있지 않을까?
버그 만들기 part 1
gcc와 clang에서 지역 변수를 스택에 할당하는 순서가 다른 점을 이용해서 간단하 버그를 만들어보자. 준비물은 다음과 같다.
- 카운터 변수. 함수의 지역 변수
- 배열. 함수의 지역 변수
- 인덱스를 벗어난 배열 조회 off-by-one error
#define MAX_LOOP_A 2
static void run_loop_a()
{
int i = 1234;
int data[MAX_LOOP_A];
g_loop_count = 0;
printf("addr i\t\t: %lx\n", (unsigned long)&i);
printf("addr data\t: %lx\n", (unsigned long)data);
for(i = 0 ; i <= MAX_LOOP_A ; ++i) {
printf("curr addr[%d]\t: %lx\n", i, (unsigned long)&data[i]);
data[i] = 0;
g_loop_count++;
if(g_loop_count > MAX_LOOP_A + 10) {
printf("ERROR: Infinitely Loop!!!\n");
break;
}
}
}addr i : 7ffe5f427c7c
addr data : 7ffe5f427c80
curr addr[0] : 7ffe5f427c80
curr addr[1] : 7ffe5f427c84
curr addr[2] : 7ffe5f427c88배열의 크기가 2일때 gcc에서는 무한루프는 발생하지 않는다.
addr i : 7ffc94e7f2cc
addr data : 7ffc94e7f2c4
curr addr[0] : 7ffc94e7f2c4
curr addr[1] : 7ffc94e7f2c8
curr addr[2] : 7ffc94e7f2cc
curr addr[1] : 7ffc94e7f2c8
curr addr[2] : 7ffc94e7f2cc
curr addr[1] : 7ffc94e7f2c8
curr addr[2] : 7ffc94e7f2cc
curr addr[1] : 7ffc94e7f2c8
curr addr[2] : 7ffc94e7f2cc
curr addr[1] : 7ffc94e7f2c8
curr addr[2] : 7ffc94e7f2cc
curr addr[1] : 7ffc94e7f2c8
curr addr[2] : 7ffc94e7f2cc
ERROR: Infinitely Loop!!!배열의 크기가 2일때 clang에서는 무한루프가 발생한다. (테스트를 위해서 적당히 루프를 돌다 종료시켰다)
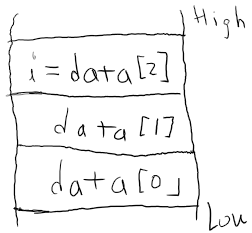
왜 clang에서는 무한루프가 발생했는지 확인하기 위해서 메모리 구조를 간단하게 그려보았다. (나 그림 못그리는거 아니까 알아서 이해하자)
data[0]의 주소는 7ffc94e7f2c4 이다. data[1]의 주소는 data[0]에서
4바이트 증가한 7ffc94e7f2c8 이다. data[2]의 주소는 data[1]에서
4바이트 증가한 7ffc94e7f2cc 가 될것이다. 그리고 7ffc94e7f2cc 는
지역변수 i의 주소와 동일하다. 즉, data[2] = 0 는 i = 0 과 같은
동작이고 이것때문에 배열 카운터가 리셋되어서 무한루프가 발생한다.
버그 만들기 part 2
여기서 끝나면 재미없다. 배열의 크기가 바꿔서 다시 테스트 해보자. 배열의 크기를 2에서 4로 바꿨다.
#define MAX_LOOP_B 4
static void run_loop_b()
{
int i = 1234;
int data[MAX_LOOP_B];
g_loop_count = 0;
printf("addr i\t\t: %lx\n", (unsigned long)&i);
printf("addr data\t: %lx\n", (unsigned long)data);
for(i = 0 ; i <= MAX_LOOP_B ; ++i) {
printf("curr addr[%d]\t: %lx\n", i, (unsigned long)&data[i]);
data[i] = 0;
g_loop_count++;
if(g_loop_count > MAX_LOOP_B + 10) {
printf("ERROR: Infinitely Loop!!!\n");
break;
}
}
}addr i : 7ffdfc5c630c
addr data : 7ffdfc5c6310
curr addr[0] : 7ffdfc5c6310
curr addr[1] : 7ffdfc5c6314
curr addr[2] : 7ffdfc5c6318
curr addr[3] : 7ffdfc5c631c
curr addr[4] : 7ffdfc5c6320배열의 크기가 4일떄 gcc에서는 무한루프가 발생하지 않더라.
addr i : 7fffea9c10bc
addr data : 7fffea9c10a0
curr addr[0] : 7fffea9c10a0
curr addr[1] : 7fffea9c10a4
curr addr[2] : 7fffea9c10a8
curr addr[3] : 7fffea9c10ac
curr addr[4] : 7fffea9c10b0배열의 크기가 4일때 clang에서는 무한루프가 발생하지 않는다. 이전과는 동작이 완전히 달라졌다. clang로 실행했을때의 메모리 주소값을 잘 보면 지역변수 배열data와 지역변수 i가 연속적으로 배치되어있지 않다. 지역변수가 연속적으로 배치되어있지 않기 때문에 잘못된 메모리를 건드리긴 했지만 i를 건들진 않아서 무한루프가 발생하진 않았다.
버그 만들기 summary
위의 실행 결과를 정리하면 다음과 같다.
- clang, gcc의 지역변수를 스택에 할당하는 정책은 다르다.
- 같은 컴파일러라고 해도 상황에 따라서 지역변수가 스택에 들어가는 방식이 달라진다.
- 지역 변수를 선언한 순서와 변수가 스택에 배치되는 순서는 관계 없다.
- 지역변수가 스택에 연속적으로 배치된다는 보장은 없다.
- 지역 변수가 스택의 어디에 배치될지는 아무도 모른다.
- 모든 것은 컴파일러한테 달려있다.
스택에 지역변수가 어떻게 배치될지 모른다는 것과 잘못된 배열 참조를 합친 버그의 진정한 의미는 언제 어떤 식으로 터질지 아무도 모른다는거에 있지 않을까?
해결책
스택에 할당되는 지역 변수의 주소값에 의해서 발생시킬수 있는 버그를 생각해봤는데 잘못된 배열 참조 말고는 생각나는게 없더라. (배열 아니면 지역 변수의 주소값을 직접 다루지 않으니까) 그래서 잘못된 배열 참조를 막을수 있는 방법 몇가지를 정리했다.
코드를 잘 짜자
for(i = 0 ; i <= ARRAY_SIZE ; ++i)
배열을 접근하다 인덱스를 넘은 것이 버그의 원인이다. 코드를 짤때 신경써서 실수를 하지 않으면 버그가 생기지 않을 것이다.
하지만 이걸 해결책이랍치고 적어놓으면 무책임하다. 아무리 신경쓴다고 해도 사람은 실수를 하게 된다. 내가 실수를 안해도 다른 사람이 내 몫의 실수도 대신 해줄거다.
자료구조 변경 + 수동으로 메모리 주소 접근 제거
data[i] = 0;
실수로 배열의 크기을 넘어서 참조하려고 할때 이를 감지할수 있으면 버그를 빨리 잡을 수 있을 것이다. 배열에 접근할때 인덱스가 올바른 범위인지 확인하면 어떨까?
C배열을 사용하면 수동으로 주소를 이용해서 메모리에 접근하는걸 피할수 없다. 만약 C배열을 사용하지 않도록 코드를 바꾸면 주소를 수동으로 조작할 일이 없으니 사고터질 가능성이 줄어들지 않을까?
std::vector::at
C 배열을 버리고 std::vector 를 사용하자. 그리고 std::vector의 요소에
접근할때는 at() 함수를 이용하자. at() 함수는 잘못된 인덱스로 접근을
시도하면 예외를 던진다.
Returns a reference to the element at specified location pos, with bounds checking. If pos not within the range of the container, an exception of type std::out_of_range is thrown.
#include <vector>
#include <stdexcept>
void vector_ver()
{
int i = 1234;
std::vector<int> data(2);
for(i = 0 ; i <= 2 ; ++i) {
int &val = data.at(i);
val = 0;
}
}
int main()
{
try {
vector_ver();
} catch(std::out_of_range e) {
printf("range exception\n");
}
return 0;
}C배열은 스택에 할당되지만 std::vector은 내부에서 동적할당을 수행한다. C배열에는 없던 부하가 생겼다. std::vector 대신 다른걸 사용해보는건 어떨까?
custom std::array
C++ TR1에 std::array가 추가되었다. 지금은 std::array이 C++11에 포함되어 있어서 대부분의 컴파일러에서 사용 가능할 것이다.
std::array는 C배열과 마찬가지로 스택에 할당된다. std::array를 직접
사용하면 좋겠지만 std::array의 operator[] 는 인덱스 범위 검사가
포함되어있지 않다. 그래서 아래와 같이 std::array를 상속받아서
operator[] 안에 범위 검사를 구현할 수도 있다.
#include <cassert>
#include <array>
template<typename T, std::size_t N>
struct my_array : std::array<T, N> {
T &operator[](std::size_t n) {
assert(n >= 0 && n < N);
return (*static_cast<std::array<T,N>*>(this))[n];
}
const T&operator[](std::size_t n) const {
assert(n >= 0 && n < N);
return (*static_cast<const std::array<T,N>*>(this))[n];
}
};
int main()
{
int i = 1234;
my_array<int, 2> data;
for(i = 0 ; i <= 2 ; ++i) {
data[i] = 0;
}
return 0;
}루프 인덱스를 없애자
for(i = 0 ; i <= ARRAY_SIZE ; ++i)
루프를 돌면서 배열을 조회하려다가 잘못된 인덱스로 접근해서 버그가 생긴 것이다. 우리는 배열의 처음부터 끝까지 루프하는게 목적이잖아? 그렇다면 루프 인덱스를 없애고 배열 전체를 루프하는게 있으면 버그를 피할수 있지 않을까?
std::for_each
algorithm 헤더에는 std::for_each 라는게 있다. 시작 iterator 의 끝 iterator, 그리고 루프동안 수행할 작업을 인자(함수, functor)로 넣어주면 루프를 대신 돌려준다.
#include <array>
#include <algorithm> // for std::for_each
struct Functor {
void operator()(int &x) {
x = 0;
}
};
int main()
{
int i = 1234;
std::array<int, 2> data;
std::for_each(data.begin(), data.end(), Functor());
return 0;
}C++11 부터는 lambda가 있어서 functor를 쓰지 않아도 된다. 나머지는 동일하다.
#include <array>
#include <algorithm> // for std::for_each
int main()
{
int i = 1234;
std::array<int, 2> data;
std::for_each(data.begin(), data.end(), [](int &x) {
x = 0;
});
return 0;
}foreach loop (ranged-based for statements)
기껏 std::for_each를 만들어놨더니 사람들이 안써서 그랬는지 C++11 부터는 새로운 for 문법이 추가되었다. ranged-based for 문을 이용하면 루프 카운더 없이 루프를 사용할수 있다.
#include <array>
int main()
{
int i = 1234;
std::array<int, 2> data;
for(int &x : data) {
x = 0;
}
return 0;
}다양한 컴파일러, 다양한 환경에서 테스트
컴파일러 경고 수준은 최대한 높이는 것이 좋다. 모든 플랫폼에 대해 경고 수준을 허용할 수 있는 한도 내에서 최대한 높게 설정할것 (Visual Studio의 경우는 /W, gcc는 -Wall 등). 컴파일러 중에는 특히 더 까다로운 것들이 있다. 같은 코드를 여러 컴파일러들로 컴파일해보면, 코드를 실행시키기 전에라도 버그를 발견할 가능성이 높아진다. 그리고 경고를 오류로 취급하게 하는 옵션도 활성화시킬 것. 그러면 코드의 깨끗함을 유지할수 있으며, 별 문제가 없어 보이는 코드를 다른 팀에게 배포했는데 그 팀이 작업하는 플랫폼에서 오류와 경고가 발생하는 일을 피할 수 있다.
Game Programming Gems 4 - 1.4 커다란 크로스플랫폼 라이브러리의 설계와 유지
gcc로 컴파일했을때와 clang으로 컴파일했을때의 실행 결과가 다르면 코드에 버그가 있을수 있다. 여러 컴파일러에서 컴파일해서 유닛테스트와 합쳐서 돌려보고 그 결과가 동일한지 확인하면 컴파일러에 따라서 행동이 바뀌는 버그를 찾는데 도움이 될 것이다.
옛날에 cocos2d-x로 아이폰 게임 개발했었다. 개발은 주로 윈도우에서 visual
studio로 하고 테스트는 xcode(+clang)로 컴파일해서 iOS에서 수행했다.
어느날 똑같은 함수인데 윈도우와 iOS에서 다른 동작을 하는 버그가
발견되었다. sizeof(wchar_t) 가 윈도우와 iOS에서 달라서 생기는
버그였는데 iOS, 윈도우에서 동시에 쓰던 코드였기 때문에 쉽게 찾을수
있었다.
컴파일할때 옵션을 -W -Wall 로 설정했음에도 경고없이 컴파일이 되었기
때문에 v1에서는 컴파일 옵션을 언급하지 않았다. RD 님의 조언에 따라
clang의 경우 -Weverything 옵션을 넣고 다시 시도해 보았다. 하지만
clang은 코드의 문제점을 찾아내지 못했다. 간단한 잠재적 위험요소는
컴파일러가 잡아낼수 있지만 off-by-one error는 아직 컴파일러가 못
찾아내는거같더라.
Static code analytics
for(i = 0 ; i <= ARRAY_SIZE ; ++i)
사람이 코드를 잘 읽어보면 잘못된 인덱스로 배열을 참조하는 버그가 있다는걸 찾아낼 수 있을 것이다. 그렇다면 코드를 잘 읽고 잘못된 인덱스로 배열을 참조하는 버그가 있다는걸 찾아내는 툴을 만들면 되지 않을까? 사람이 코드를 발로 짜도 툴이 코드를 잘 읽고 문제가 생기는 지점을 찝어주면 사고칠 확률이 줄어들겠지?
이런 기능이 정적 코드 분석(Static code analysis)이고 이런 기능을 하는게 코드 정적 분석기(Static code analyzer)이다.
컨셉은 단순하지만 제대로 구현하는건 그렇지 않다. 몇가지 코드 정적 분석툴을 이용해서 위의 잘못된 인덱스로 배열을 접근하는 코드를 검사해보았다. cppcheck, splint는 이 버그를 잡아내지 못했다.
실망하기는 이르다. 위의 버그를 잡아낼수 있는 정적 분석 도구가 세상에
없는건 아니다. Gimpel Software 에서 개발한
FlexeLint for C/C++ 를 이용하면 위의 버그를 잡아낸다.
Links
- stack overflow: Order of local variable allocation on the stack
- stack overflow: Bound checking of std::array in “Debug” version
- cppreference std::vector::at
Sources
본문의 테스트에 사용한 코드이다. 직접 받아서 테스트해볼수 있다.
https://github.com/if1live/libsora.so/tree/master/content/development/stack-allocation-voodoo-magic
Environment
본문에 나오는 코드를 테스트한 환경이다. 다른 환경에서 테스트했을때도 같은 결과가 나온다는 보장이 없으니 참고용으로 적어둔다.
clang 3.4
$ clang --version
Ubuntu clang version 3.4-1ubuntu3 (tags/RELEASE_34/final) (based on LLVM 3.4)
Target: x86_64-pc-linux-gnugcc 4.8.4
$ gcc --version
gcc (Ubuntu 4.8.4-2ubuntu1~14.04) 4.8.4History
- v1 : 2015/10/07
- 초안 작성 및 공개
- v2 : 2015/10/10
- 소스 원본 링크 추가
- 컴파일러 옵션 관련 추가
- 이해하기 쉽도록 무한루프 버그 코드 수정
- special thanks : RD